Beginners guide to Web Scraping (Cheerio, User-Agents)
Now more than ever, web scraping leads the charge in revolutionary advancements—from training top-of-the-news LLMs like DeepSeekAI and ChatGPT to transforming medical research and improving pricing intelligence. It's fuelling a software market now valued at over $700M.
And of course, given the grey area nature of web scraping, prioritising anonymity as you learn to scrape is a no-brainer.
This piece kicks off the Anonymous Web Scraping series, where I delve into fundamental web scraping techniques while safeguarding your Personally Identifiable Information (PII), thus avoiding blocks.
Subsequent instalments will include:
-
How to Export scraped data (JSON, CSV, Database) for further analysis or integration.
In this instalment, you will learn the step-by-step process of scraping static websites anonymously using Javascript, Cheerio and User-Agents header rotation.
Prerequisites
To follow along easily through the course of this tutorial, ensure you have the following background knowledge and tools ready:
- Javascript basics. Understanding the basics of Javascript and using
npmfor dependency management. - HTML and CSS fundamentals. Familiarity with the
htmlDOM andcssselectors. - A Code Editor. You can use any code editor of your choice. I'll be using VS Code on macOS for this tutorial.
- Node.js installed. Have the Node.js runtime installed. If not, download and install Node.js to get started.
Set up a Node.js Project
First, create a new folder called anonymous-scraper by running the code below in your terminal:
mkdir anonymous-scraper
Navigate into the folder:
cd anonymous-scraper
Initialize the Node.js project:
npm init -y
This adds a package.json file in the root folder that helps track your dependencies, and manage installed libraries. You should also ensure that the "type": "module" field is included in your package.json file as this tutorial will use ES6 modules.
While Node.js's flexibility gets questioned in comparison to Python web
scraping, its single-threaded model — powered by the multi-threaded V8 engine
— makes it an ideal choice for the async-heavy scraping needs.
Now let's begin.
Static-site scraping with Cheerio, Fetch, and User-agent rotation
I split the core scraping tutorials into two tiers, each offering a distinct degree of anonymity and scraping complexity. With this approach, I aim to provide you with a thorough understanding of techniques and strategies across both dimensions.
This tier explores static site scraping, using the fetch API for http requests, Cheerio for static HTML parsing, and the user-agents library for user-agents rotation.
User agent rotation involves cycling through a set of user agent strings — unique identifiers that specify the client's software and device details — to simulate requests from various browsers and devices.
For context, here's a typical user agent string:
Mozilla/5.0 (Macintosh; Intel Mac OS X 14_7_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36
The user agent rotation technique masks your real masks your real user agent details, reducing the risk of detection, IP tracking and potential IP ban by target websites. And that's why it's a good starting point for anonymous scraping.
I opted for the built-in fetch API (from Node v18) over alternatives like
Axios and Superagent because it is lightweight and doesn't require
additional libraries. If you're using an older Node.js version, you may need
to install node-fetch to use
fetch().
That being said, let's write some code.
Step 1: Create the scraper file and install the necessary dependencies
Create a new file named anon-scraper1.js and open the file. You can do this by running the following command on your terminal:
touch anon-scraper1.js
Next, run the following command to install the cheerio and user-agents packages:
npm install cheerio user-agents
Step 2: Fetch the HTML Content of Your Target Website
To fetch the HTML of your target website, use the fetch API to send a request to the website, retrieve its HTML, and prepare it for parsing. See code below:
const fetchStaticData = async () => {
try {
// Send GET request to fetch website data
const PAGE_URL = 'https://books.toscrape.com/'
const response = await fetch(PAGE_URL)
// Extract text data from the response
const data = await response.text()
// Log the extracted data
console.log(data)
} catch (error) {
// Handle errors
console.error('Error fetching Data ->', error)
}
}
fetchStaticData()
The fetchStaticData() async function sends a GET request to the specified PAGE_URL, then it retrieves the HTML response as text and logs it to the console. The try-catch block handles any error during the process.
Use the node command to run the script in your terminal:
node anon-scraper1.js
The terminal will log the raw HTML content of the target web page, including headings, links, and other elements. Expect many lines of output — that's perfectly normal.
Notice the similarity between the returned html data and the devtools "elements" tab resource when you visit the page itself. This is because fetch() retrieves the raw HTML just as a browser would when you load the page.
Next, we'll extract specific elements from the page and put the user-agents rotation technique to test.
Step 3: Scrape data from a specific HTML DOM element
In this section, you will find and extract data from a page element using the Cheerio jquery-like syntax. First, open the webpage in a Chromium-based browser (e.g., Chrome, Edge, etc.), inspect the elements, and identify the CSS selectors as shown in the image below with the article > h3 > a and p.price_color selectors.
Once you have the CSS selectors, modify the fetchStaticData() function to include the scraping logic as seen below:
// import cheerio and user-agents
import * as cheerio from 'cheerio'
import UserAgent from 'user-agents'
const fetchStaticData = async () => {
try {
const PAGE_URL = 'https://books.toscrape.com/'
// Create random user-agents
const userAgent = new UserAgent()
const randomUserAgent = userAgent.random().toString()
// Send GET request with the random user-agent
const response = await fetch(PAGE_URL, {
headers: {
'User-Agent': randomUserAgent,
},
})
const html = await response.text()
// Load the HTML into Cheerio for parsing
const $ = cheerio.load(html)
const selectors = { name: 'article > h3 > a', price: 'p.price_color' }
// Extract last product data
const lastProduct = {
name: $(selectors.name).last().text(),
price: $(selectors.price).last().text(),
}
console.log('lastProduct -> ', lastProduct)
} catch (error) {
// Handle errors
console.error('Error fetching Data ->', error)
}
}
fetchStaticData()
This version utilizes the user-agents library to generate a randomUserAgent header, masking the request origin. Cheerio then parses the raw HTML into a DOM-like structure to extract the "name" and "price" of the page's last product. Here's the output you should get:
lastProduct-> { name: "It's Only the Himalayas", price: "£45.17" };
You've just completed a static webpage element scrape. I recommend rerunning the script multiple times while logging randomUserAgents on the console so you observe the variations and peculiarities in the generated user-agents.
Now let's do something a little more interesting.
Scrape multiple DOM elements
Scraping multiple elements follows the same logic as using a standard loop — an iteration logic. We'll extract the name and price of all products on the page using the Cheerio .each() method to loop through each product element (.product_pod) and retrieve the required fields. Here's a snippet to demonstrate:
const fetchStaticData = async () => {
try {
// fetch and parse HTML with cheerio...
// Extract all product data from the first page
const selectors = { name: 'article > h3 > a', price: 'p.price_color' }
const productElement = $('.product_pod')
// create a products array
const products = []
productElement.each(function () {
const name = $(this).find(selectors.name).text()
const price = $(this).find(selectors.price).text()
products.push({ name, price })
})
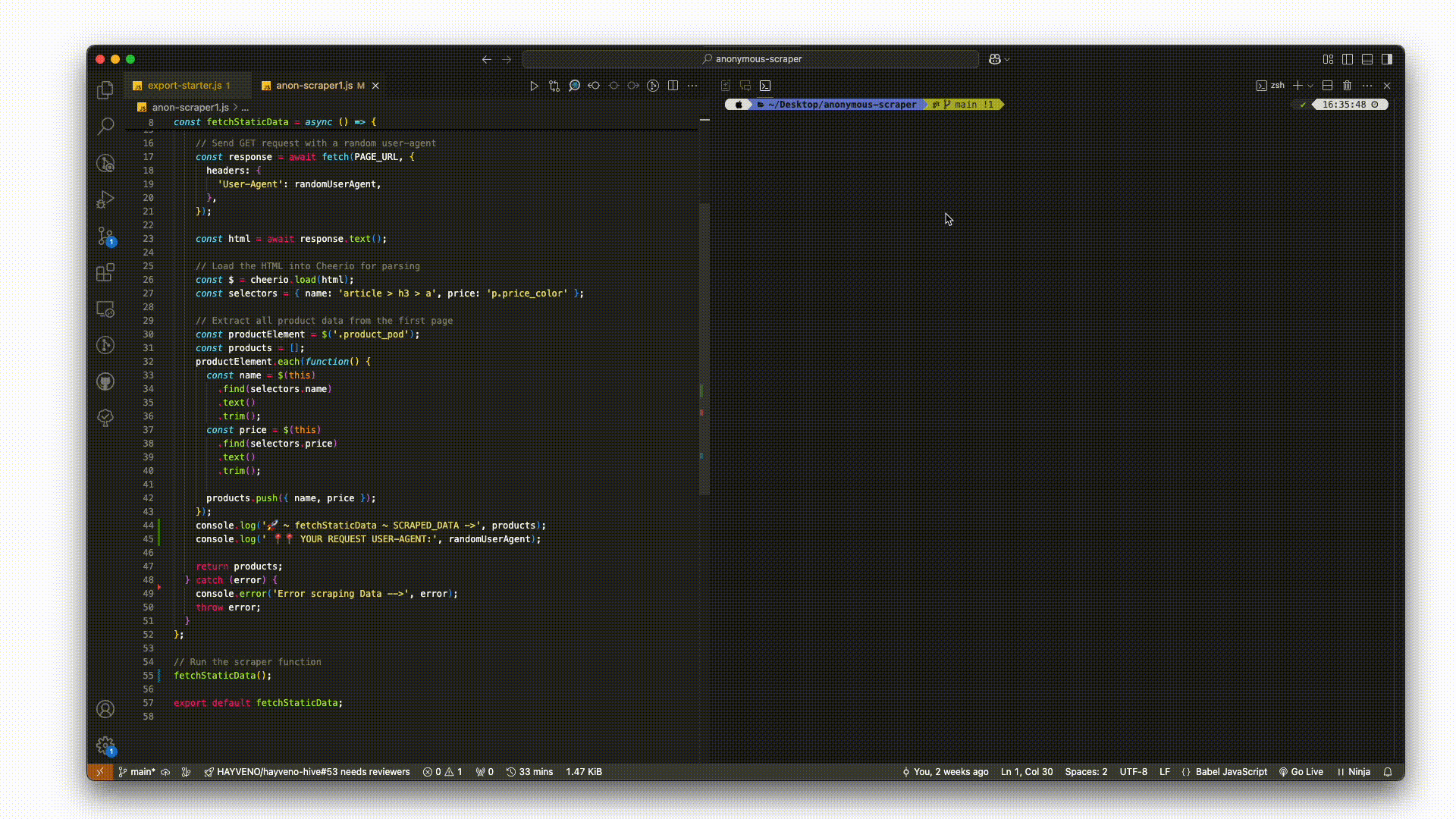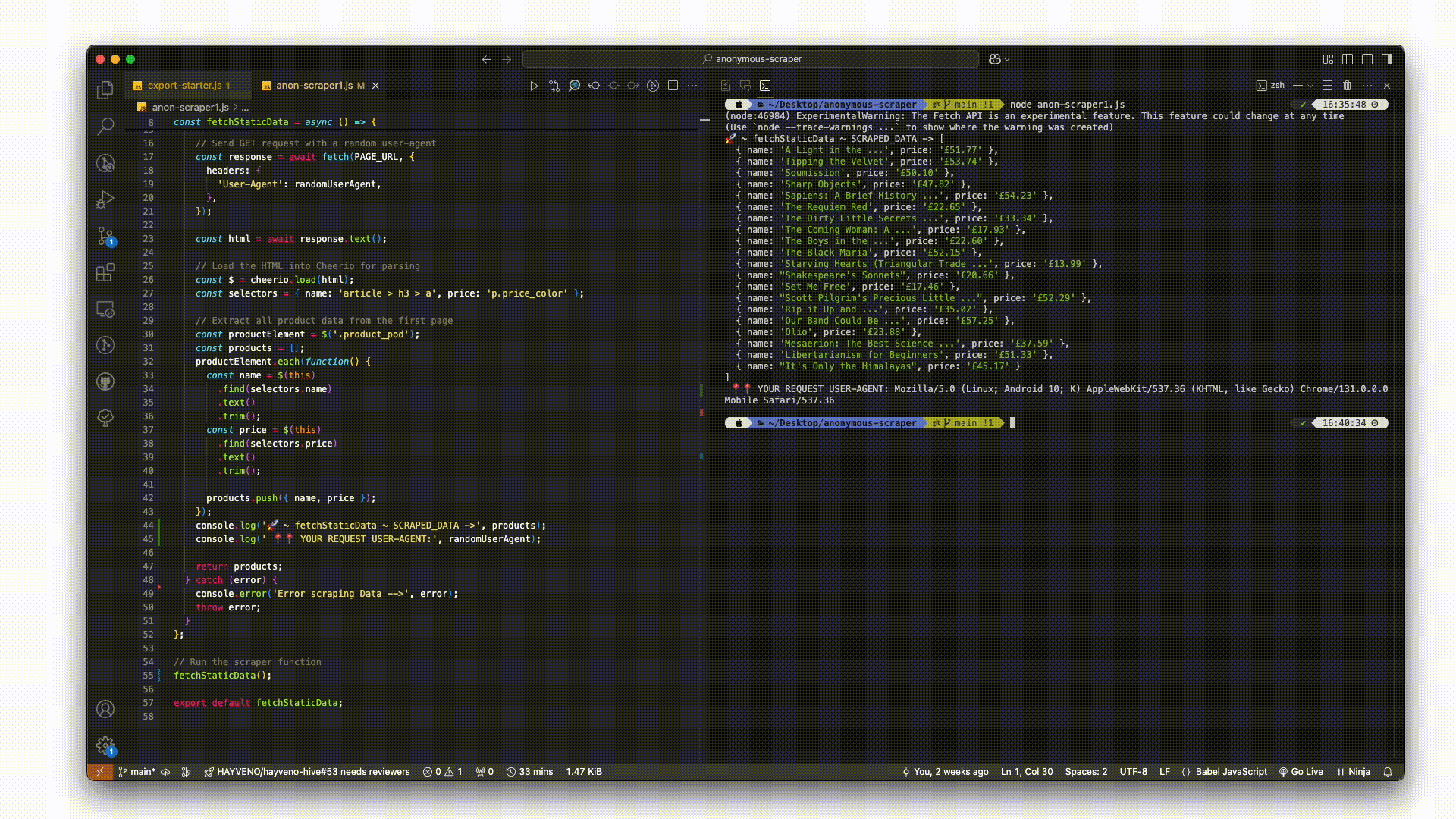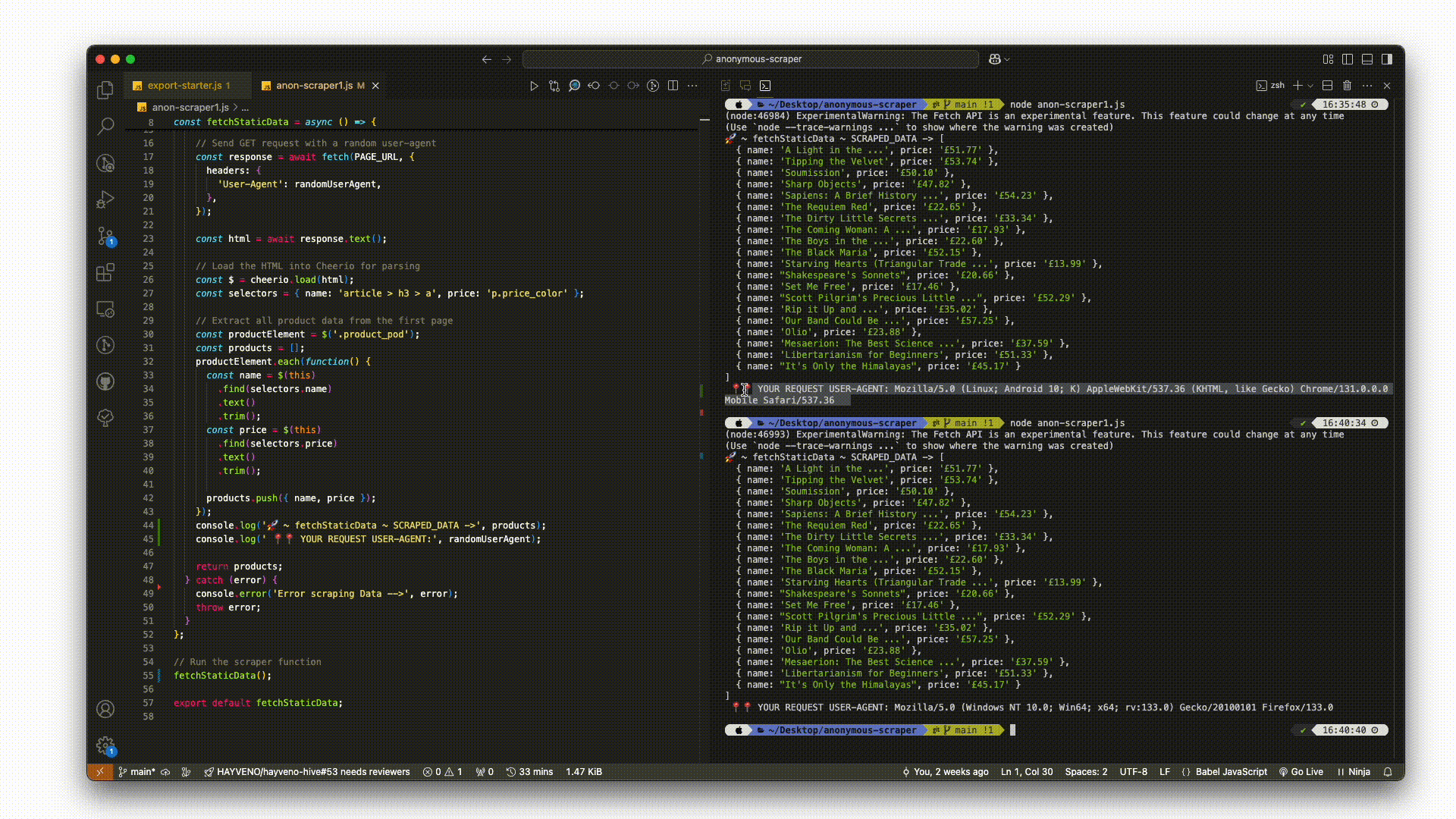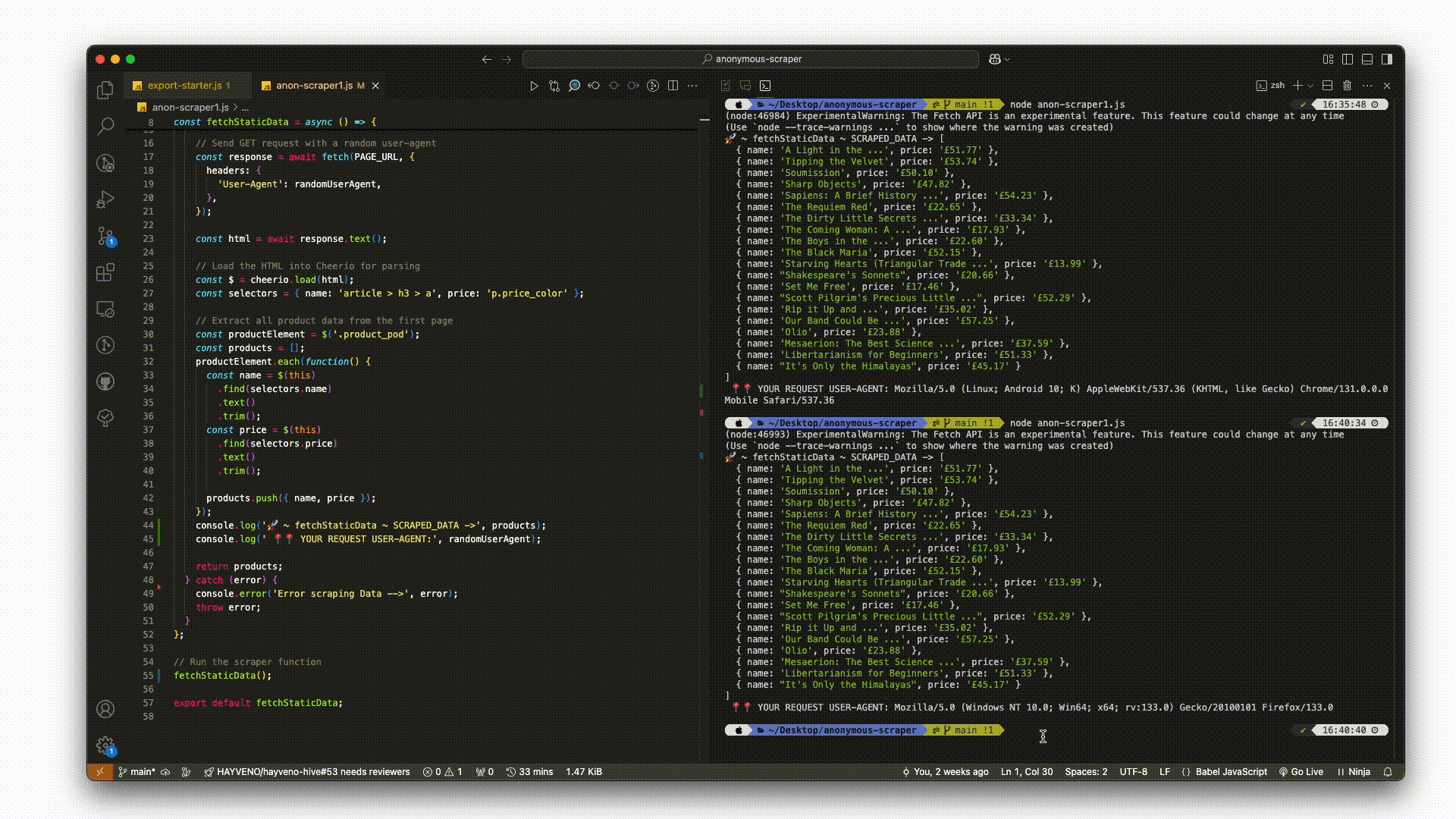
console.log('products ->', products)
} catch (error) {
// Handle errors
console.error('Error scraping Data -->', error)
}
}
Notice how I use this and not the actual DOM element selector - a common pattern with loop methods to contextually reference the current DOM element within the loop.
The logged array should look like this:
products -> [ { name: 'A Light in the ...', 'price: '£51.77' },
{ name: 'Tipping the Velvet', price: '£53.74' },
{ name: 'Soumission', price: '£50.10' },
{ name: 'Sharp Objects', price: '£47.82' },
// other products on the page...
]
That's about it! You've completed a static webpage scrape—mission accomplished, promise fulfilled. I recommend taking it a step further by extracting additional fields, like images and availability, to broaden your understanding even more.
Check out the final source code of this tutorial here.
Limitations of this approach
As I stated earlier, while it's a good place to start, the Cheerio-fetch-user-agents approach is not ideal for professional use due to a number of reasons, including:
- Static HTML only. This approach is limited to scraping content in the raw html and cannot handle client-side rendered content or any content that requires javascript execution.
- Low-Level Anonymity. User-agent rotation offers minimal privacy, leaving devices exposed to tracking via browser-fingerprinting, IP monitoring, or behavioural analysis.
Disclaimer: This guide is for educational use only. Scraping public data is generally accepted, but always ensure you read the website terms and follow legal regulations.
Conclusion
So far we've explored the basics of scraping anonymously using Fetch, Cheerio, and User-agents rotation. But while this method serves as a great starting point, it would fall short for most modern websites as you have learned with its static content and anonymity limitations.
In the next instalment (Tier-2), we'll dive into a more sophisticated, safe, and professional approach that can handle the complexities of advanced scraping and effectively address these limitations. Be there.